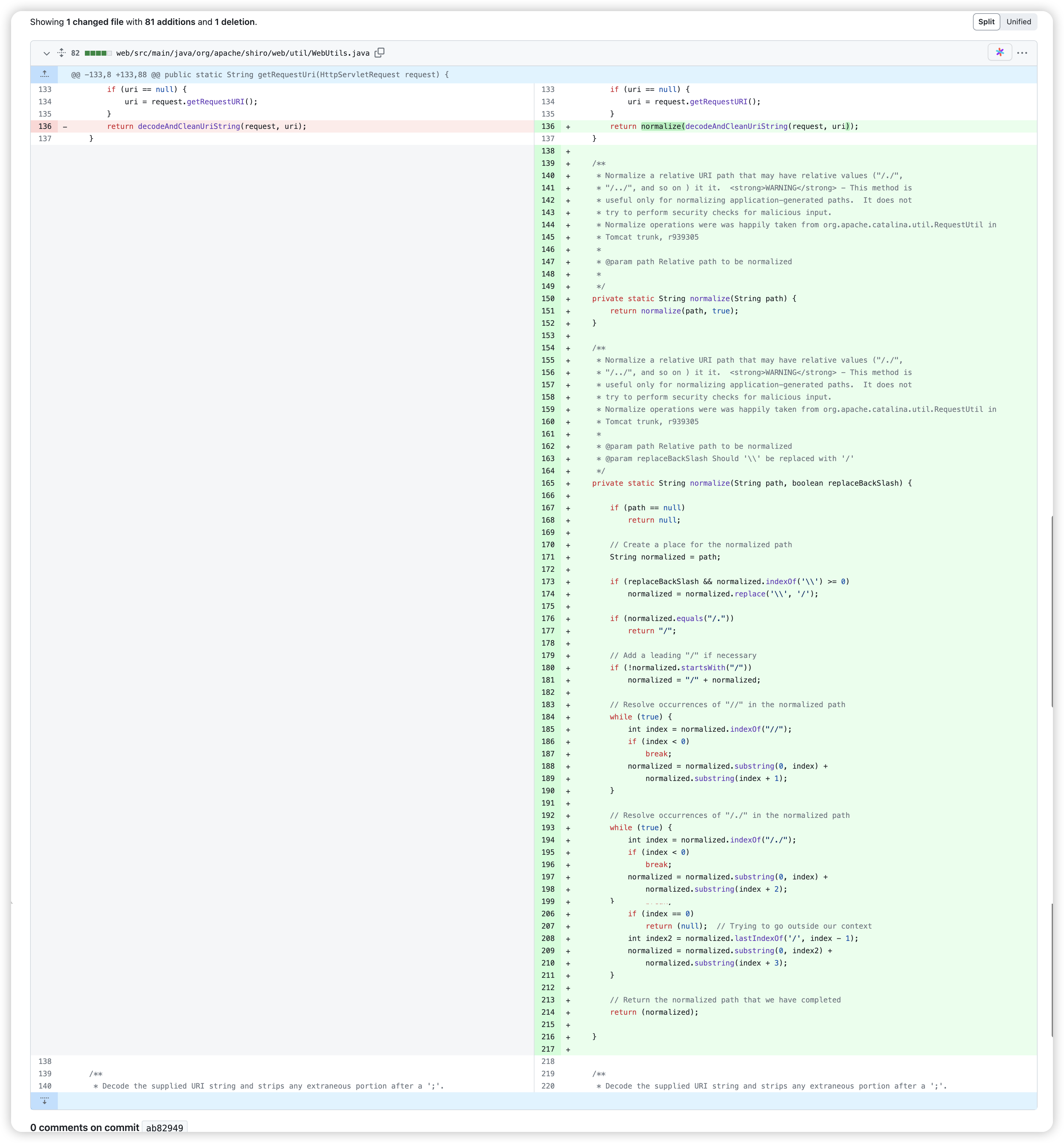
CVE-2010-3863
https://github.com/vulhub/vulhub/tree/master/shiro/CVE-2010-3863
https://xz.aliyun.com/t/11633#toc-2
0x00 概述
Shiro 没有规范化 uri 路径,导致攻击者可以使用/./ /../ / //进行认证绕过。
影响范围:
- Shiro before 1.1.0
- JSecurity 0.9.x
0x01 漏洞分析
org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain
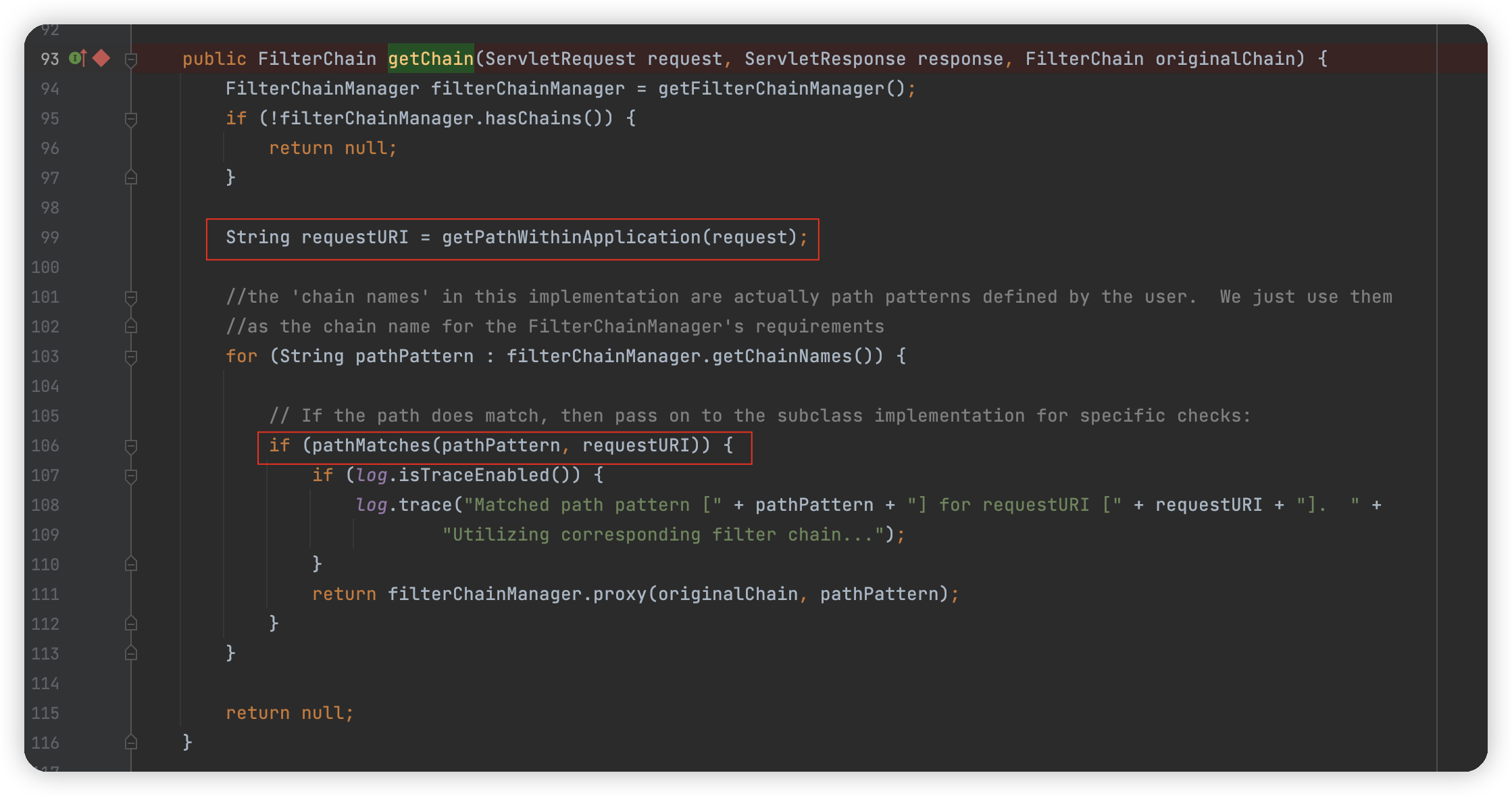
99行通过getPathWithinApplication获取 requestURI,然后在 106 行进行路径匹配,先追一下路径获取。

这里调用了WebUtils.getPathWithinApplication进行获取
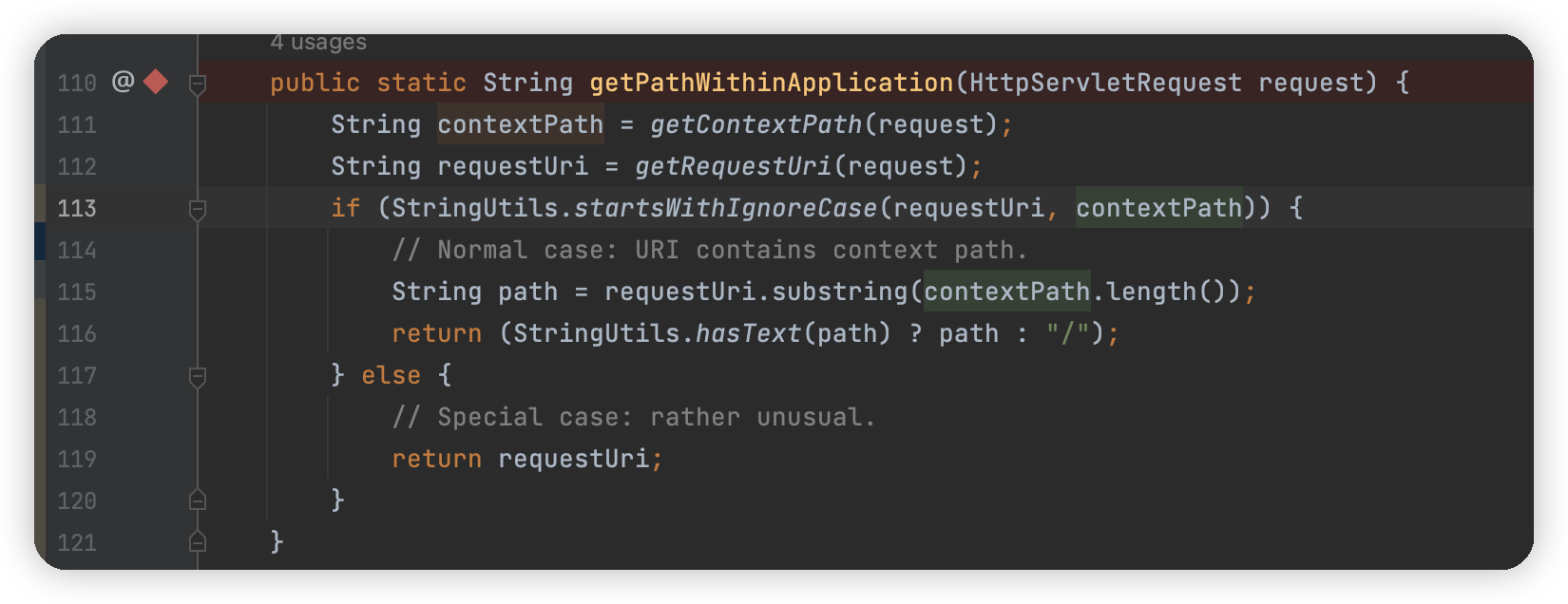
这里 111 行获取 contextPath,112 行获取 requestUri,后续进行比对是否是以 contextPath 进行开头,是的话就截取掉,无关痛痒,重要的是getRequestUri 中是否对路径做了处理
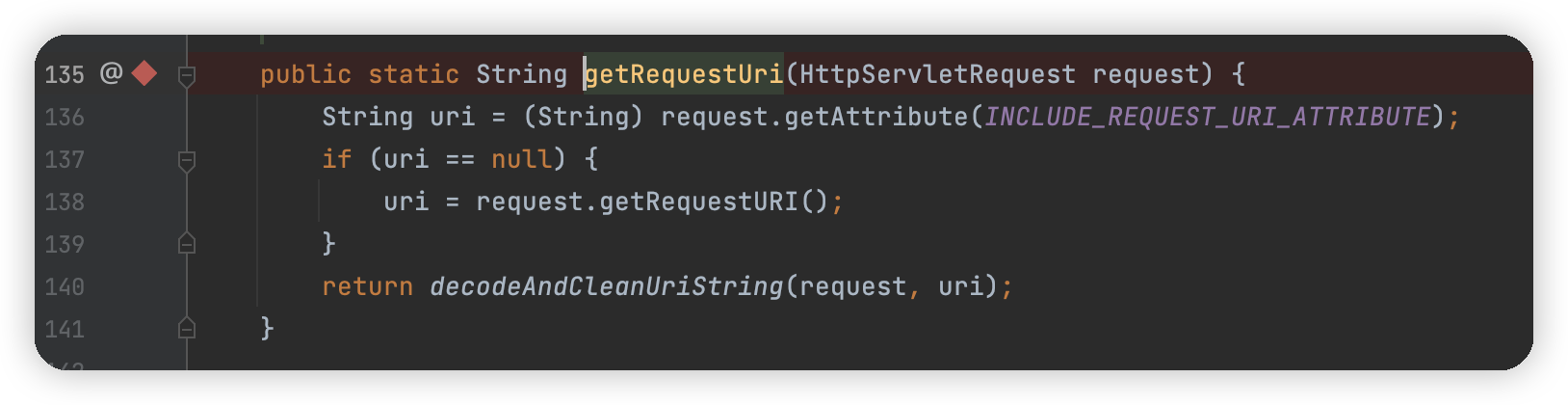
首先是从属性中取是否有javax.servlet.include.request_uri属性,没有就直接调用request.getRequestURI,然后用decodeAndCleanUriString处理

这里仅仅只是将 uri 中的 html 编码解析,之后根据;进行截取,没有其他的规范化处理,如果一旦出现特殊字符,就可能导致出现问题。
然后我们回到getChain的处理,来看一下规则匹配的实现,这一步就是根据 pattern 和 path 进行匹配,如果设置了/**的匹配,后面都会匹配成功
protected boolean doMatch(String pattern, String path, boolean fullMatch) {
if (path.startsWith(this.pathSeparator) != pattern.startsWith(this.pathSeparator)) {
return false;
}
String[] pattDirs = StringUtils.tokenizeToStringArray(pattern, this.pathSeparator);
String[] pathDirs = StringUtils.tokenizeToStringArray(path, this.pathSeparator);
int pattIdxStart = 0;
int pattIdxEnd = pattDirs.length - 1;
int pathIdxStart = 0;
int pathIdxEnd = pathDirs.length - 1;
// Match all elements up to the first **
while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
String patDir = pattDirs[pattIdxStart];
if ("**".equals(patDir)) {
break;
}
if (!matchStrings(patDir, pathDirs[pathIdxStart])) {
return false;
}
pattIdxStart++;
pathIdxStart++;
}
if (pathIdxStart > pathIdxEnd) {
// Path is exhausted, only match if rest of pattern is * or **'s
if (pattIdxStart > pattIdxEnd) {
return (pattern.endsWith(this.pathSeparator) ?
path.endsWith(this.pathSeparator) : !path.endsWith(this.pathSeparator));
}
if (!fullMatch) {
return true;
}
if (pattIdxStart == pattIdxEnd && pattDirs[pattIdxStart].equals("*") &&
path.endsWith(this.pathSeparator)) {
return true;
}
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
} else if (pattIdxStart > pattIdxEnd) {
// String not exhausted, but pattern is. Failure.
return false;
} else if (!fullMatch && "**".equals(pattDirs[pattIdxStart])) {
// Path start definitely matches due to "**" part in pattern.
return true;
}
// up to last '**'
while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
String patDir = pattDirs[pattIdxEnd];
if (patDir.equals("**")) {
break;
}
if (!matchStrings(patDir, pathDirs[pathIdxEnd])) {
return false;
}
pattIdxEnd--;
pathIdxEnd--;
}
if (pathIdxStart > pathIdxEnd) {
// String is exhausted
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
}
while (pattIdxStart != pattIdxEnd && pathIdxStart <= pathIdxEnd) {
int patIdxTmp = -1;
for (int i = pattIdxStart + 1; i <= pattIdxEnd; i++) {
if (pattDirs[i].equals("**")) {
patIdxTmp = i;
break;
}
}
if (patIdxTmp == pattIdxStart + 1) {
// '**/**' situation, so skip one
pattIdxStart++;
continue;
}
// Find the pattern between padIdxStart & padIdxTmp in str between
// strIdxStart & strIdxEnd
int patLength = (patIdxTmp - pattIdxStart - 1);
int strLength = (pathIdxEnd - pathIdxStart + 1);
int foundIdx = -1;
strLoop:
for (int i = 0; i <= strLength - patLength; i++) {
for (int j = 0; j < patLength; j++) {
String subPat = (String) pattDirs[pattIdxStart + j + 1];
String subStr = (String) pathDirs[pathIdxStart + i + j];
if (!matchStrings(subPat, subStr)) {
continue strLoop;
}
}
foundIdx = pathIdxStart + i;
break;
}
if (foundIdx == -1) {
return false;
}
pattIdxStart = patIdxTmp;
pathIdxStart = foundIdx + patLength;
}
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
}
匹配成功之后会进入filterChainManager.proxy(originalChain, pathPattern),根据 pathPattern 获取认证配置,然后通过一系列 filter 进行访问。
0x02 修复分析
修复就是在处理 requestURI 时,对/./ /../ / //进行截取处理